→ スマホ用は別頁
|
=== 読者が配色を変更したい場合 ===
◎外側の色を変えるには,次の色をクリック
《Rの関数の♪〜軽い解説》
== 具体例で,とにかく動くもの == R version 4.0.3, 4.0.4Patched ----- この教材の最終更新年月日:2021.5.08
• この教材では,体験・入門のレベルで,30分から1時間ほどで「そこそこ分かる」ものを目指す.
• Rに付属のhelpが英語で,そのGoogle翻訳が"読めない"ので,自分自身に分かる書き方に直す. • 正確なレファレンスが必要な人は,Rのコンソールからhelpを読んでください. 関数 hist( )
ヒストグラムを表示する.
書き方他にもあるが,主なものを紹介する hist(x, ←数値から成るベクトル breaks= , ←階級分けの境界となる数値 right= , ←a<x≦b型 か a≦x<b型か xlim=c(始点, 終点), ←X軸の目盛りの範囲 ylim=c(始点, 終点),←Y軸の目盛りの範囲 main="", ←タイトル文字列 xlab= "", ←X軸ラベル ylab= "") ←Y軸ラベル主な引数 (1)第1引数には,ヒストグラムによって階級分けしてほしい数値のセットをベクトルで書く. 【例1】 x<-c(0.5, 1.2, 1.3, 2.4, 3.1, 3.2) #←6個の小数 hist(x) |
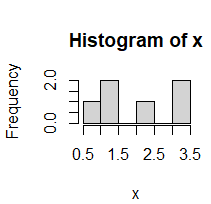 一般に,データの個数をNとするとき,分布の傾向を見やすくするための階級数kは,「スタージェスの公式」が目安とされている.
一般に,データの個数をNとするとき,分布の傾向を見やすくするための階級数kは,「スタージェスの公式」が目安とされている.
この例では,階級幅は0.5になっている. (2)第2引数もしくは名前付き引数breaks=として,階級分けの境界となる数値(下端,上端も)をベクトルで書く.
【例2】
x<-c(0.5, 1.2, 1.3, 2.4, 3.1, 3.2)
hist(x, breaks=c(0, 1, 2, 3, 4))
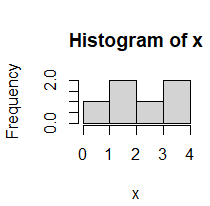 例2のようにbreaksを指定すると,右図のように整数で区切られた階級で表示される.
例2のようにbreaksを指定すると,右図のように整数で区切られた階級で表示される.なお,1,3,5, ..., 9のように初項1, 末項9, 公差2の等差数列を階級の境界線とするには breaks=seq(1, 9, by=2) 初項0, 末項4, 項数5の等差数列を階級の境界線とするには breaks=seq(1, 9, length=5) |
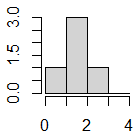 データでは2が3個あるはずであるが,ヒストグラムでは1が3個あるように見える.これは,right=の引数を省略した場合
データでは2が3個あるはずであるが,ヒストグラムでは1が3個あるように見える.これは,right=の引数を省略した場合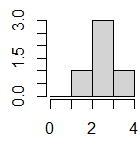 right=Fを指定すると,
right=Fを指定すると,