→ スマホ用は別頁
|
=== 読者が配色を変更したい場合 ===
◎外側の色を変えるには,次の色をクリック
《Rの関数の♪~軽い解説》
== 具体例で,とにかく動くもの == R version 4.0.3, 4.0.4Patched ----- この教材の最終更新年月日:2021.5.08
• この教材では,体験・入門のレベルで,30分から1時間ほどで「そこそこ分かる」ものを目指す.
• Rに付属のhelpが英語で,そのGoogle翻訳が"読めない"ので,自分自身に分かる書き方に直す. • 正確なレファレンスが必要な人は,Rのコンソールからhelpを読んでください. 関数 sample( ), sample.int( )
標本抽出関数,ランダムなベクトルを作る
書き方整数の疑似乱数を作る sample(x, size, replace = FALSE, prob = NULL)主な引数 (1) 第1引数には,ベクトルを書く. (2)第2引数には,それらのベクトルから抽出する標本の個数を書く
【例1】
第1引数を連続整数ベクトルとするときは,次の例2のようにコロンを使って書くと便利
sample(c(1,2,3,4,5), 2) ⇒ {1,2,3,4,5}から2個取り出す ⇒ 3 5 など(結果は毎回変わる)
【例2】
※通常の使い方でsample( )関数を使うと,上記の例1,例2のように疑似乱数的に毎回結果が変わる.これに対して,乱数を用いたシミュレーションの再現テストをやる場合のように「同じ出方が必要な場合」は,set.seed(number)により,numberの所に分析者が決めた特定の整数を繰り返し使うと,同じ結果を得ることができる.
sample(1:10, 3) ⇒ 1以上10以下の整数から3個取り出す ⇒ 9 10 3 など(結果は毎回変わる) |
(3)第3引数もしくは名前付き引数でreplace=により,復元抽出(=TRUEまたは=T),非復元抽出(=FALSEまたは=F)の別を指定する.既定値(省略された場合の値)は,replace=FALSEすなわちデフォルトで非復元抽出になっているので注意. 非復元抽出では,「一度出たものは,その後は出ない」から,「標本が重複することはない」「それまでに出ているものを見れば残りに出るものが予想できる」ので,完全に公平であるが乱数代わりに使うことはできない.また,元のベクトルの要素数lenght(x)よりも大きな個数の標本nを指定するとエラーになる.
【例3】
サイコロの目が同様な確からしさで出るかどうかというような実験をするには,復元抽出replace=Tを指定する.疑似乱数的に使うには,replace=Tとする.
sample(1:5, 5) ⇒ 1~5の整数から5個取り出す ⇒ 3 4 2 5 1(4番目まで見たら5番目は出るまでに分かる)
【例4】
要約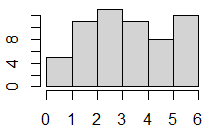 サイコロを60回投げる実験をRで行い,出た目の回数をヒストグラムに表示する
サイコロを60回投げる実験をRで行い,出た目の回数をヒストグラムに表示するsample(1:6, 60, replace=T) hist(x, breaks=c(0,1,2,3,4,5,6)) ⇒ 右図 引数が「省略されている場合」や「想定外の書き方になっている場合」の結果を覚えるのは大変. 第3引数までは「省略せずに書く」と決めると,簡単になる.特に,replace=は重要
sample(ベクトル, 選び出す標本の数,
非復元:replace = FALSE 復元:replace=TRUE) |